Django- F() Expression
What is the F() Expression? First let me explain to you what are Query Expressions are, these expressions let you use value or computation to be used in the update, create and filters, order by, annotation, aggregation. F() object represent the value of the model fields or annotated columns. It lets you help to not load the value of the field into the python memory rather directly handles in the Database query.
How to use the F() Expression? To use the F expression you have to import them from the from django.db.models import F and have to pass the name of the field or annotated column as argument, and it will return the value of the field from the database, without letting know the python any value. Let some example.
from django.db.models import F
# Documents is the table which have the details of the document submitted by user from the registrey portal for GYM membership
# We need update the count of the document submitted by the user with pk=10091
# without using F Expression
document = Documents.objects.get(user_id=10091)
document.document_counts += 1
document.save()
# Using F expression
document = Documents.objects.get(user_id=10091)
document.document_counts = F('document_counts') + 1
document.save()
Benefits of the F() Expression.
- With the help of F expression we can make are query clean and concise.
from django.db.models import F
document = Documents.objects.get(user_id=10091)
document.update(document_counts=F('document_counts') + 1)
#Here we also have achieved some performance advantage
#1. All the work is done at database level, rather than throwing the value from the database in the python memory to do the computation.
#2. Save queries hit on the database.
- F Expression can save you from the race condition. Consider a scenario where multiple user access your database and when bother user access the Document object for the user 10091, the count value is two, when user updates the value and save it and other user does the same the value will be saved as three not Four because when both user fetches the value its two.
# user A fetch the document object, and value of document_counts is two.
document = Documents.objects.get(user_id=10091)
document.document_counts += 1
document.save()
# after the operation value of document_counts is three
# Code running prallerly, User B also fetch the object, and value of document_counts is two.
document = Documents.objects.get(user_id=10091)
document.document_counts += 1
document.save()
# after the operation value of document_counts is three
# But actually value should be Four, but this is not the case using F expression here will save use from this race condition.
- F Expression are persistent, which means the query persist after the save operation, so you have to use the refreshfromdb to avoid the persistence.
document = Documents.objects.get(user_id=10091)
document.document_counts = F('document_counts') + 1
document.save()
document.document_validation = 0
document.save()
# This will increase the value of *document_counts* by two rather then one as the query presists and calling save will trigger the increment again.
- More example of F Expression in action with filter, annotate query.
from django.db.models import F
# annotation example
annotate_document = Document.objects.filter(created_by=F('created_by_first_name') + F('created_by_last_name')
# filter example
filter_document = Documents.objects.filter(total_documents_count__gt=F('valid_documents_count'))
That's all about the F Expression, it is pretty handy and helps you improve the performance, by reducing value loading in the memory and query hit optimization, but you have to keep an eye over the persistent issue, which I assume will not be the case if you are writing your code in structured way.
Cheers!
 – It's up to you how you want to maintain your journal, Some entries example to sort out your expenses.
– It's up to you how you want to maintain your journal, Some entries example to sort out your expenses.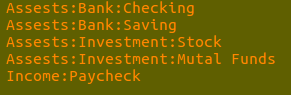 – You can also plan your budget in the ledger and can automate the transaction, if you are geeky enough you can write a code to read the spreadsheet shared by your bank to populate the ledger.
– Ctrl-C Ctrl-O Ctrl-R for report generation, you can find more about reports
– You can also plan your budget in the ledger and can automate the transaction, if you are geeky enough you can write a code to read the spreadsheet shared by your bank to populate the ledger.
– Ctrl-C Ctrl-O Ctrl-R for report generation, you can find more about reports